
Git Wizardry III: The marauder’s graph
In my previous post, I said that a GUI client should show the commit graph, among other things, in its main interface. But, what does this graph represent? Let’s have a look at how Git organizes your changes.
Every time you record your changes, a new commit is created in the Git repository. (This word is also used as a verb, so you can say that you commit your changes to the repository.)
A commit is easy to visualize because it is, oversimplifying, a snapshot of your working directory. It contains a tree with the files as they were in your file system. It also includes metadata such as an associated message, a timestamp or the author’s name and email.
But there is one more thing recorded in a commit: references pointing to other commits, called the parent commits. In the simplest case, a commit has a single parent, that represents the immediately previous commit. Thus, you can pick any commit in the repository and follow the history until you reach the initial commit, that will not have a parent.
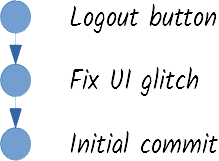
This is an important difference with other version control systems: commits are not ordered, but they are interconnected through reference(s) to their parent commit(s). Technically speaking, commits are nodes that form a directed acyclic graph.
Each Git client will try its best to draw this graph. Apart from the obvious parent commit relationship, clients usually take into account sensible information, such as recorded timestamps. But two clients may show you different representations of the same graph, and both may be right.
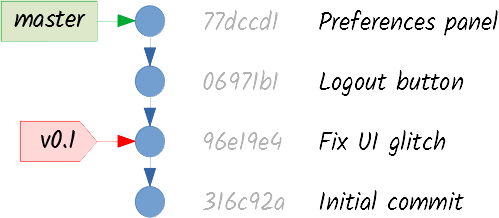
If commits are unordered, how can you uniquely identify them? Git takes all the information in a commit (the file tree, the message, the author…) and calculates a SHA-1 hash. This gives a 40-hexadecimal-character result, which looks like 316c92a708f83a31b72c798f016f66146d8eb541. This is not a very practical ID, so as long as there aren’t conflicts, you can use only the first few characters of the commit. Git requires at least four characters, and most clients show six or seven, like 316c92a. The larger the repository, the more characters you’ll need to uniquely refer to a commit.

Let’s be honest: a seven-hexadecimal-character ID is not practical either. Fortunately, you hardly ever need to refer to a commit using its ID. Git lets you create special references to commits that you consider important in the repository.
A tag is a reference pointing to a commit that represents an interesting moment in history, for example, a release. Once a tag is created, it should not be moved or deleted. (It can be moved or deleted, but it shouldn’t, especially if it has been synchronized to other repositories.)

A branch is a reference pointing to a commit that represents a line of work, like a new feature. Unlike tags, branches are constantly moving and may be deleted if they are not needed anymore.

A branch called master is automatically created in a new repository. Although you are not forced to use it, and you could even delete it if you wanted to, many developers just go along with master for their main line of work.
Now, if you record new changes:
-
First, the new commit is created, using the commit pointed by the branch as its parent commit.
-
Then, the branch points to the new commit.
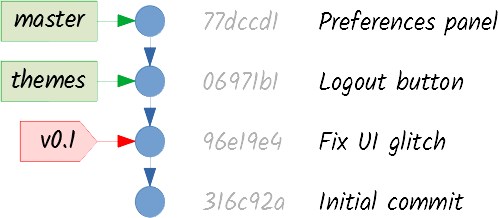
To start a new line of work, you just create another branch. Since branches are just references, this action does not modify the graph at all. You just specify which commit you want to point to (using its ID, or selecting it with your mouse if you have a GUI client), you give your branch and name and you have it.
A branch that is created to add a new feature is commonly known as a feature branch. For example, imagine you want to add themes to your application. Besides, you’re not very happy with the last commit you added and want to start working from earlier in time. You can create a themes branch like this:
You may be wondering, if you have two or more branches, how does the repository know which one it should use for new commits? To solve this problem, only one of them is considered to be the current branch (Git implements this using another special reference in the repository called HEAD, but you can ignore that for now). Your GUI client should clearly show which your current branch is, and should make it easy for you to check out (i.e., switch to) another branch.
Now you can use your branches to alternatively record changes to either line of work:
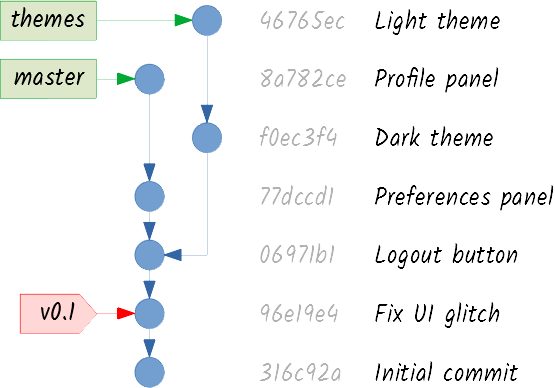
Eventually, you may want to address this divergence. Suppose you’re satisfied with the work on themes and you want to integrate it into master. In Git parlance, you want to merge the themes branch into the master branch. Just tell your client that you want to do that, and you will end up with a commit graph like this:
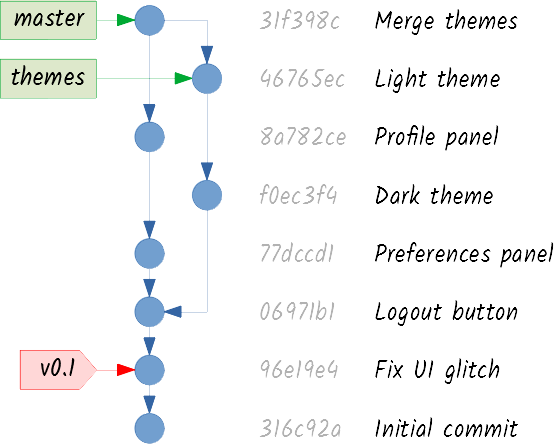
That last commit doesn’t look like the others, does it? It is called a merge commit. It is the result of merging two branches, so it has two parents. Git will try to reconcile both lines of work, but if there are any conflicts, it will refuse to create the merge commit unless you solve them. (Solving conflicts is unpleasant, but a good Git client makes this daunting task much easier.)
Pay attention to one detail: while master is pointing to the commit that has integrated both lines of work, themes is still pointing to the last commit of the feature. Merging only works one way. You have merged themes into master, but not the other way around. If this seems strange to you, try and think about it this way:
-
You (and other developers working on
themes) can continue working in the feature while being isolated from the changes in the rest of the repository. -
You (and other developers working on
master) can benefit from partial integrations of the new feature as many times as wanted. Just remember that, if new commits are created onthemesafter a merge, you need to merge the branch again.
Take a deep breath and make sure you’ve understood everything so far. From my experience, developers find it difficult to see a branch just as a reference. They navigate the graph using their mouse or their finger, while saying: “These commits on the left are the master branch, these ones on the right are the themes branch.” That’s wrong. In this example, you can state some facts about master:
-
It is a line of work pointing to commit
31f398c. -
If you want to log all the history that has led to this commit, you have to consider all the commits, the ones on the left and the ones on the right.
-
For any of those commits, and for any commit in the repository, it’s impossible to know how they were added. Maybe through
master. Maybe throughthemes. Maybe through a branch that doesn’t exist anymore. -
In fact, it’s impossible to know if
masterorthemesexisted 5 minutes ago. They may have just been created.
Branches are just references, that’s all! I guess the human brain associates the word branch with the lengthy part of the tree, so maybe another name would have been better. Who knows. Too late.
Back to work. Once you consider the feature is finished, and all the commits in the feature branch have been merged, it can be deleted. Although it is not necessary, deleting merged branches helps you keep your repository clean and tidy.
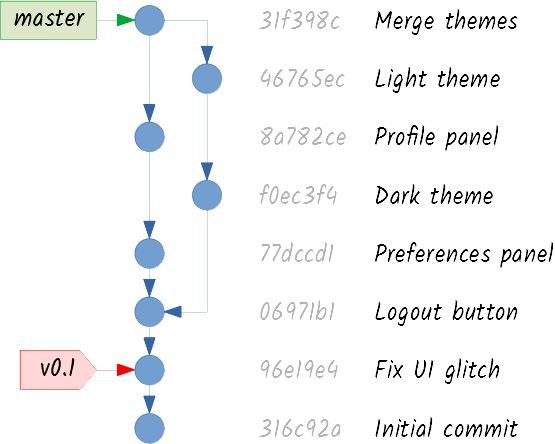
What happens if you delete a branch that has not been merged? You may end up with unreachable commits, that will be deleted by the Git garbage collector. Let’s see how this works.
One important thing you must never forget is that you navigate the graph starting from branches or tags. Once you reach a commit, you can navigate to its parents, if it has any, but you can’t navigate to its children (it is a directed graph). In fact, a commit does not even know if it has any children.
Taking this into account, the garbage collector looks for unreachable commits and consider them not to be useful anymore. For example, if you had deleted the themes branch before merging it, you would have effectively deleted commits f0ec3f4 and 46765ec, since there would have been no way to reach them through any branch or tag. (Just for you to know, unreachable commits are not immediately deleted. You can recover them if you get a branch or tag pointing to them before the garbage collector sweeps them away. But that’s high-level wizardry.)
When deleting a branch, most Git clients will try to evaluate if it is safe, will show you some kind of warning, but won’t stop you if you decide to go ahead. So be careful not to lose your work.
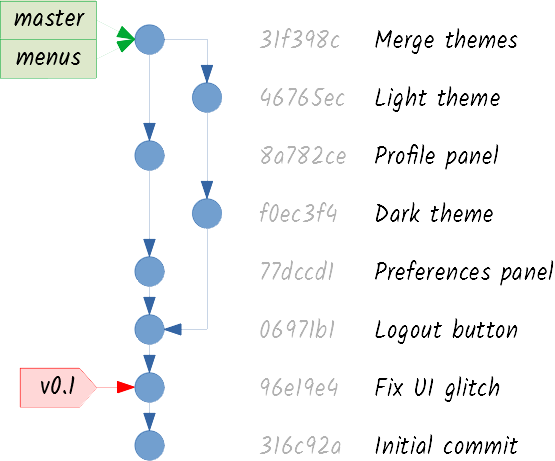
Now imagine you want to add another feature. You create a menus branch, this time pointing to the same commit as master:
You create some commits on the new branch:
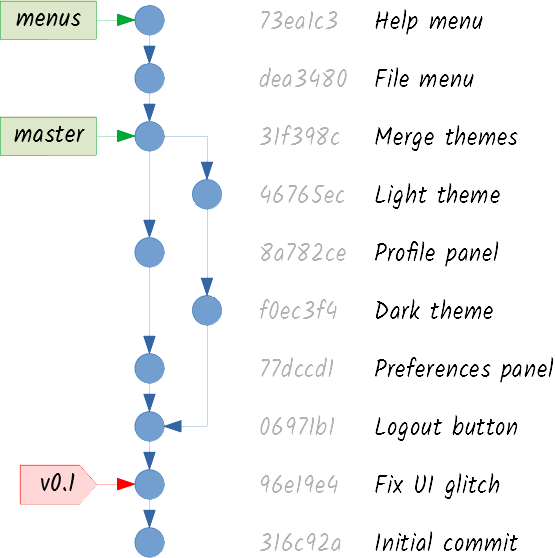
And then you tell your client that you want to merge menus into master:
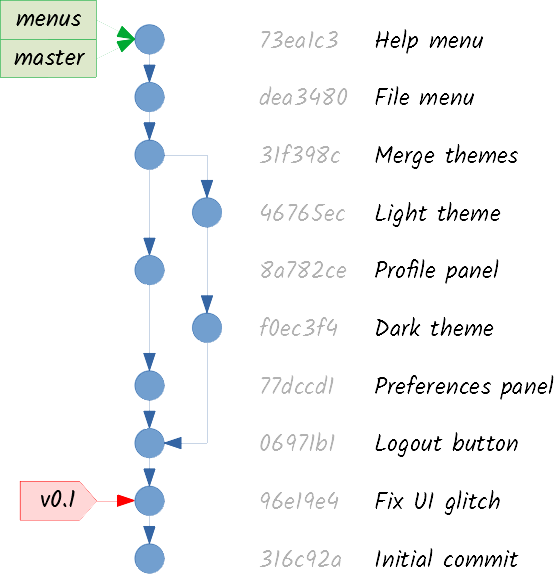
Something different has happened this time. Since there was no divergence between master and menus, there aren’t any possible conflicts. Git does not need to create a merge commit, and can merge both lines of work simply by making master point to the same commit menus is pointing to. This is called a fast-forward merge.
Although the merge process has been different, the outcome is conceptually the same: master is pointing to a commit that has integrated both lines of work, and menus is pointing to the last commit of the feature. If the feature is considered to be finished, the menus branch can be deleted:
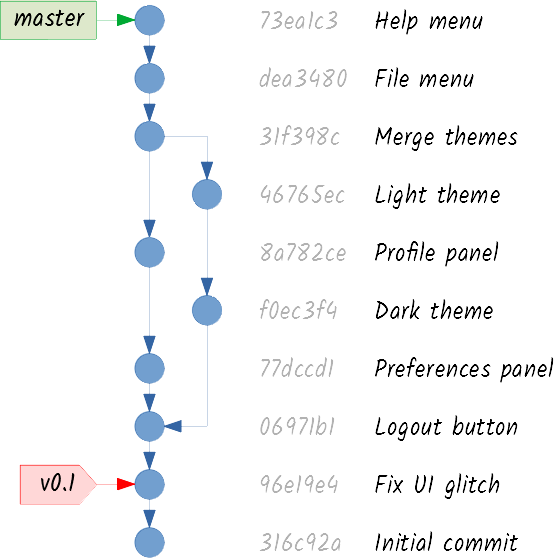
Remember the v1.0 tag you created a long time ago? Well, I have good news and bad news. The good news are that the release was a worldwide success. The bad news are that someone found a very annoying security bug.
I guess you know what you have to do! First you create a new branch pointing to the tagged commit:
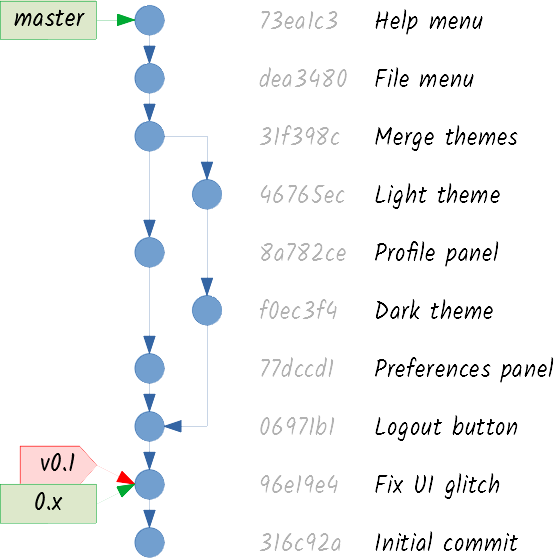
A branch that is created to patch a released version is commonly known as a maintenance branch. You can commit the required patch to the 0.x branch:
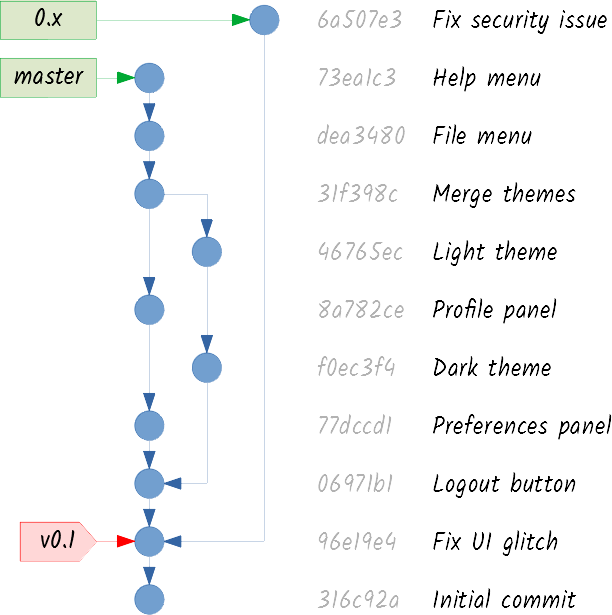
And then you tag the v0.2 version for a new release:
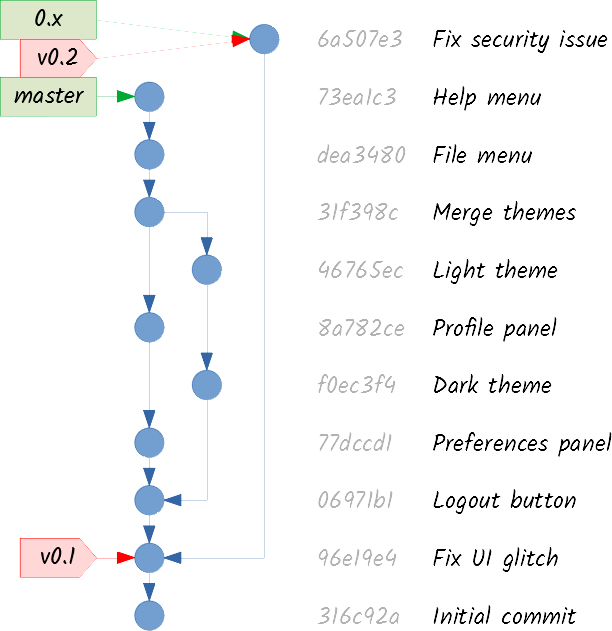
Of course, you also want the security patch applied in master, so you merge the maintenance branch:
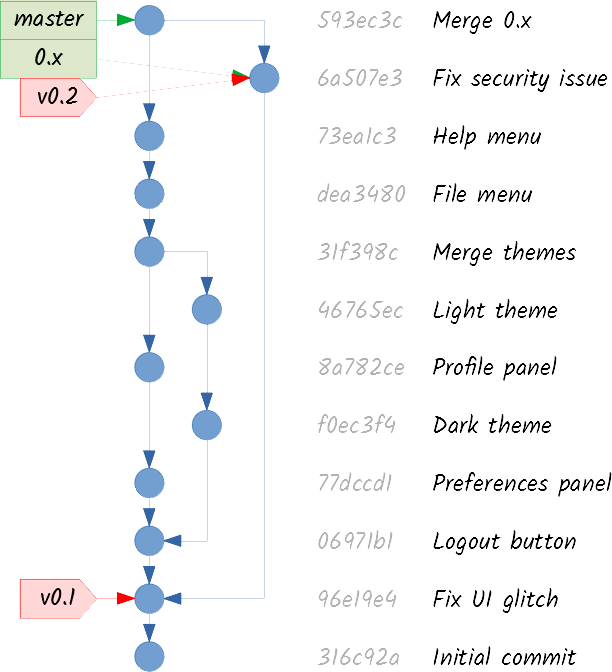
In this case, it may be useful to keep the maintenance branch, in case you (or other developers) need to apply another patch to this version. But if you delete it, you can easily recreate it in the future. Remember, branches are just references!
I’ve explained some conceptual uses of Git branches, but the possibilities are endless. You will find very elaborated workflows (like the famous git-flow), but many of them are not worth the complexity unless you’re working on a large project. Try to find a simple model that suits your needs.
In my next post, I will explore the relationship between a Git repository and its working directory.
Git Wizardry
I: Spells don’t come easy
II: Choosing the right wand
III: The marauder’s graph
IV: Working directories and where to find them
V: The three realms